
As I write this blog post, it is my understanding that the following areas are at the forefront of AI research:
Understanding human speech
Competing in strategic game systems (such as Go)
Autonomous cars
Intelligent routing in content delivery network
While the above list is not exhaustive, and while above capabilities are useful at supplementing human abilities, they do not inherently mimic humans and their innate preferences. As AI research expands into various directions, I couldn't find a project that would try to assign numeric values to images based on their inherent 'order'. In general, while individual preferences are limitless, my hypothesis was that humans typically favor certain ‘orderly’ arrangements over others. Most humans might prefer an orderly room over a messy one, and an ordered piece of clothing over a rugged one, and a symmetrical architecture over an unsymmetrical one. Let me illustrate this in a few examples below:


If this were indeed the case, then an algorithm that can classify images as such would further true AI capabilities. In this regard, the very idea of randomness needs a closer look:
"What is randomness and where does it come from? We take for granted the randomness in our reality. Randomness cannot be understood in mathematical terms. My opinion is that randomness is a manifestation of complex information processing. If perhaps what is perceived as randomness is just an exceedingly complex computation, then can it be possible to discover some accidental hidden structure in that randomness?" - Anonymous

But before we try to build an AI that scores images in the same way as humans, we also need to understand such ‘randomness’ in mathematical terms. In statistical mechanics, concrete efforts have paved the way to understand the behavior of ensemble systems over time, and in conclusion, the ‘entropy’ of a system has been linked with time itself in the second law of thermodynamics. It is intricately tied to physics, chemistry and biology, and while the precise explanations of underlying ideas is beyond the scope of this project, I’d like to point the reader towards the following quotes by Boltzmann and Lehninger:
“The general struggle for existence of animate beings is not a struggle for raw materials … nor for energy which exists in plenty in any body in the form of heat, but a struggle for [negative] entropy.” – Ludwig Boltzmann (Physicist)
"Living organisms preserve their internal order by taking from their surroundings free energy, in the form of nutrients or sunlight, and returning to their surroundings an equal amount of energy as heat and [positive] entropy." - Albert Lehninger (Biologist)
While everything so far is interesting, how do we capture symmetry algorithmically? That, of course, is the crux of the problem. From a strictly geometrical point of view, we could try to capture the Euclidean, reflectional, rotational, translational, roto-reflectional, helical, double rotation, non-isometric etc symmetries and then try to account for distortions due to the location of the viewer. But doing that would require building an algorithm from the ground-up, and that is going to require at least a few years, if not decades. I wondered if there was a shortcut to developing our AI! After all, that is the whole point of having AI think for itself!
Among the most important requirements of building AI software is the need to train it on large amounts of data coupled with extensive computing resources to train it. This naturally turned my attention to pre-trained models that could classify images. For example, VGG16 is a deep convolutional network for object recognition with a top-5 accuracy rate of over 90%.

Essentially, to put it crudely, VGG16 identifies patterns and shapes within images, and assigns them a certain label. While AI tends to be a black box that can’t be opened-up to understand the underlying logic, my hypothesis was that models such as VGG16 can be used to extract the underlying order in day-to-day objects. But to retrain VGG16 would require the availability of large, labeled datasets and enormous computing resources. Also, it would destroy VGG16’s ability to identify patterns correctly. However, by adding additional layers on top of VGG16, one could train the additional layers alone to get the desired output.
While it’d be straight-forward to add additional layers on top of VGG16, what kind of images need to be used to train this new combination of neural network layers? Ideally, I’d want the machine to label a completely random image consisting of random pixels to be labeled as zero. And I’d also the want the AI system to label a perfectly structured and neat image to be labeled as 10. However, it remains to be seen what AI’s definition of structure is!

So, I gathered a set of ‘clean’ images with definite shapes and introduced random distortions. The distortions were created using a random number generator and were applied to random parts of the image. However, the degree to which the image was distorted could be controlled, and a set of images was created for every ‘real’ image from the ImageNet dataset.

In the above slide, the image of an i-Pod is being distorted to varying degrees, and the model output was trained to assign a value of 10 to the ‘real’ i-pod image versus a value of 0 to a completely distorted image of the i-pod. To add an element of symmetry, a collection of over 400 abstract images was also used to add to the scoring process for situations in which two images being compared are otherwise similar. I obtained an accuracy of over 86% for my model’s ability to classify between ‘real’ versus ‘distorted’ images when a binary output was mapped.















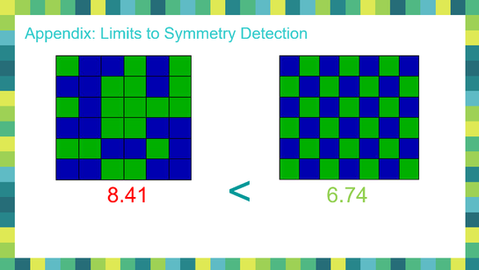
Note the higher scores for ordered images on the right, except for the last case on the bottom-right (checkered squares) wherein the model finds the image on the left to be more ordered. It appears that the algorithm finds groupings of colors to be more symmetric, but does not recognize C2 symmetry that humans would quickly identify. While a large data-set consisting of ordered vs disordered images was not available for this work, excellent results were obtained for a vast majority of straight-forward comparisons. The model was trained using GPU-intensive EC2 instances on Amazon AWS, and the Keras model was used to build a Flask app.
To the best of my knowledge, the above work is a first of it’s kind proof of concept AI.
Comments